Confusing RSS connector in Flow
During the holidays I finally found some time to play around with flow again. Currently I have running a recipe in IFTT that posts a tweet whenever I finish a book on Goodreads. The recipes uses a RSS trigger and a Twitter connector, and thus is pretty straight forward. To play around with that in Flow sounded pretty straight forward. However the RSS trigger is quite limited in Flow as I found out in the first few minutes. Flow provides the ‘when a feed item is published’ trigger that fires whenever a new item is added to a RSS feed. As Goodreads provides an RSS feed this sounded like a great way to start with. While the triggers does pickup the changes it does not return the full item, so you might be missing information when you try to process the data.
Flow RSS trigger
The flow RSS connector is standard connector that you can use to retrieve feed information and trigger a flow to run when new items are published to an RSS feed. Updates to existing data will not trigger the flow. As you can read in the documentation the trigger returns a wrapper object that contains all feed items. While your feed might return any RSS data the FeedItem that is returned in Flow will only return the following values:
- Feed ID
- Feed categories
- Feed copyright information
- Feed links
- Feed published on
- Feed summary
- Feed title
- Feed updated on
- Primary feed link
In most cases the title and summary should contain the information you need. However if you are using a Goodreads RSS you will only be returned the title of your book and some HTML in the summary but no other information. So imagine that you would hit the Goodreads RSS for read books. When you use a feedreader or visit the source of the feed you will see that it will return an array of items. Each item looks like the following:
<item>
<guid><![CDATA[https://www.goodreads.com/review/show/2770774168?utm_medium=api&utm_source=rss]]></guid>
<pubDate><![CDATA[Sat, 10 Aug 2019 03:43:40 -0700]]></pubDate>
<title>De president</title>
<link><![CDATA[https://www.goodreads.com/review/show/2770774168?utm_medium=api&utm_source=rss]]></link>
<book_id>44325896</book_id>
<book_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1552265424l/44325896._SY75_.jpg]]></book_image_url>
<book_small_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1552265424l/44325896._SY75_.jpg]]></book_small_image_url>
<book_medium_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1552265424l/44325896._SX98_.jpg]]></book_medium_image_url>
<book_large_image_url><![CDATA[https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1552265424l/44325896._SY475_.jpg]]></book_large_image_url>
<book_description><![CDATA[Het Orphan-project was in een ver verleden opgezet om de beste geheim agenten op te leiden die de Verenigde Staten ooit hebben gehad. Nu is echter op het allerhoogste niveau besloten om alle Orphans uit de weg te ruimen. Maar Evan Smoak – Orphan X – besluit terug te slaan. Zijn doelwit is niemand minder dan de man die destijds aan de wieg stond van het programma en die nu de best beveiligde persoon ter wereld is: de president van de Verenigde Staten.<br /><br />Maar president Bennett weet dat Evan het op hem heeft voorzien en zet de tegenaanval in. Hij activeert de enige figuur die de kwaliteiten en ervaring heeft om Evan op te sporen en voorgoed uit te schakelen: de eerste rekruut van het programma, Orphan A.]]></book_description>
<book id="44325896">
<num_pages>512</num_pages>
</book>
<author_name>Gregg Hurwitz</author_name>
<isbn></isbn>
<user_name>Albert-Jan</user_name>
<user_rating>5</user_rating>
<user_read_at><![CDATA[Mon, 01 Apr 2019 13:02:06 -0700]]></user_read_at>
<user_date_added><![CDATA[Sat, 10 Aug 2019 03:43:40 -0700]]></user_date_added>
<user_date_created><![CDATA[Sun, 31 Mar 2019 23:25:38 -0700]]></user_date_created>
<user_shelves></user_shelves>
<user_review></user_review>
<average_rating>4.50</average_rating>
<book_published>2019</book_published>
<description>
<![CDATA[
<a href="https://www.goodreads.com/book/show/44325896-de-president?utm_medium=api&utm_source=rss"><img alt="De president" src="https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1552265424l/44325896._SY75_.jpg" /></a><br/>
author: Gregg Hurwitz<br/>
name: Albert-Jan<br/>
average rating: 4.50<br/>
book published: 2019<br/>
rating: 5<br/>
read at: 2019/04/01<br/>
date added: 2019/08/10<br/>
shelves: <br/>
review: <br/><br/>
]]>
</description>
</item>
However when checkout the response you get from the trigger it will contain only the following information:
{
"id": "https://www.goodreads.com/review/show/2760860507?utm_medium=api&utm_source=rss",
"title": "Een oude vijand (Victor #4)",
"primaryLink": "https://www.goodreads.com/review/show/2760860507?utm_medium=api&utm_source=rss",
"links": [
"https://www.goodreads.com/review/show/2760860507?utm_medium=api&utm_source=rss"
],
"updatedOn": "0001-01-01 00:00:00Z",
"publishDate": "2019-08-10 10:31:49Z",
"summary": "\n \n <a href=\"https://www.goodreads.com/book/show/44059057-een-oude-vijand?utm_medium=api&utm_source=rss\"><img alt=\"Een oude vijand (Victor #4)\" src=\"https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1550556689l/44059057._SY75_.jpg\" /></a><br/>\n author: Tom Wood<br/>\n name: Albert-Jan<br/>\n average rating: 3.72<br/>\n book published: 2014<br/>\n rating: 5<br/>\n read at: 2019/03/23<br/>\n date added: 2019/08/10<br/>\n shelves: <br/>\n review: <br/><br/>\n \n ",
"copyright": "",
"categories": []
}
With that information it is quite hard to post a tweet as you are missing the image, and there is no information on user rating and the Author is saved to the summary.
How to retrieve all information from RSS
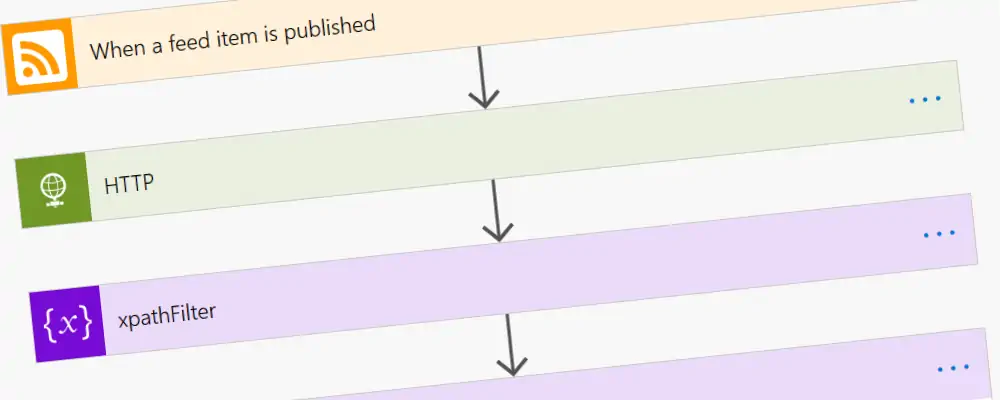
In order to retrieve all the information you require from your RSS feed you should do four actions:
- Step 1 is to have RSS trigger that fires whenever there is an update
- Step 2 is an HTTP call to retrieve the full XML for the RSS feed again
- Step 3 is to create an XPath filter that allows you to retrieve the correct item. We require an Xpath as there might have been multiple updates on the RSS feed and we need the data for the trigger.
- Step 4 is to retrieve the data based on the XPath
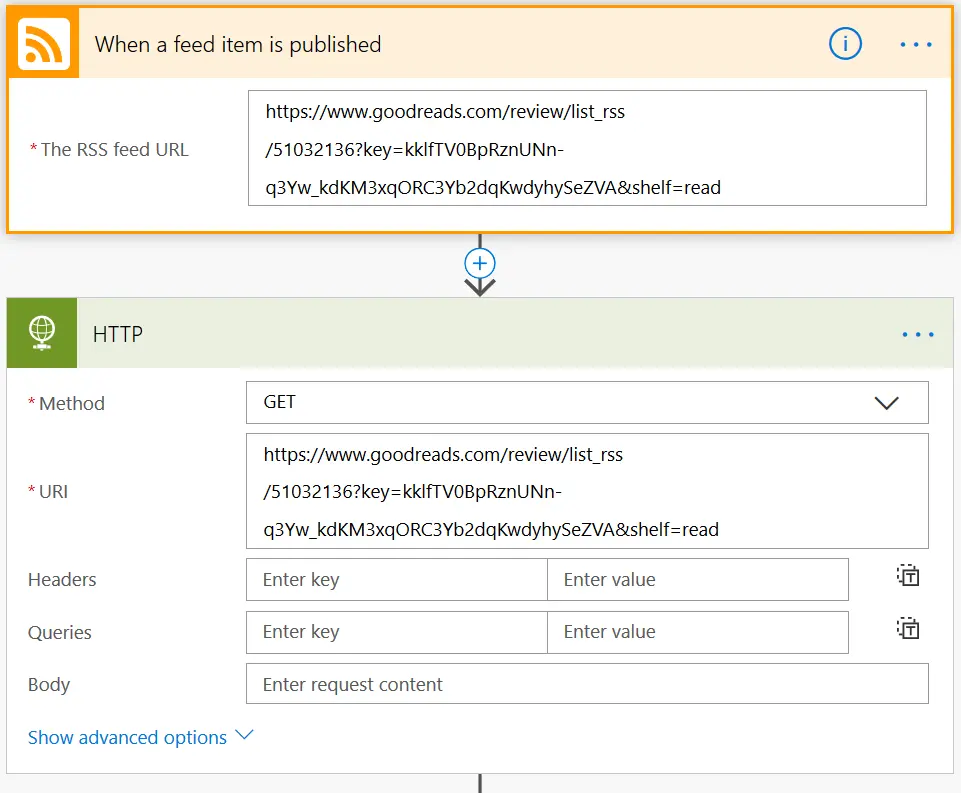
The first two actions are pretty straight forward. Just add a RSS trigger action and use the same URL in a HTTP Get call. Please be aware that the HTTP action will become a premium connector :-(.
Use XPath to get your data
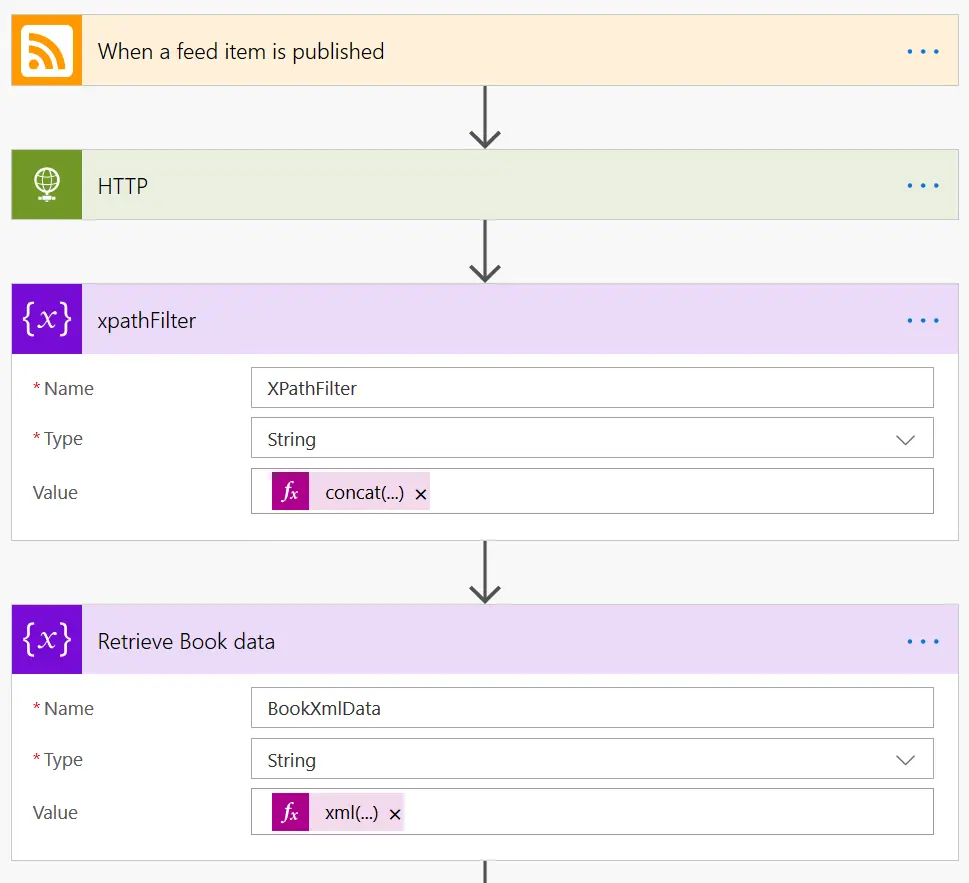
Now that we have all our XML data retrieved from the RSS feed in the HTTP Get Action we can use a XPath filter. This XPath filter for Goodreads looks as the following:
concat(’(//rss/channel/item[title = “’, triggerBody()?[’title’], ‘”])’)
As you can see it will construct a new string with the //rss/chanel/item[title=“booktitle”] XPath query. That way we you can be sure that you retrieve the correct XML. Now the next step will be to retrieve the book data element. That will be to simply apply the XPath query to the data retrieved from the HTTP request:
xml(xpath(xml(body(‘HTTP’)), variables(‘XPathFilter’))[0])
From left to right you can see that we first make sure the response is returned as xml by adding a xml wrapper around the XPath. Second the XPath query can only be done against an XML element so the HTTP Body is wrapped in a xml wrapper as well. And as an XPath can return multiple values make sure to add an [0] to retrieve the first item that matches the XPath.
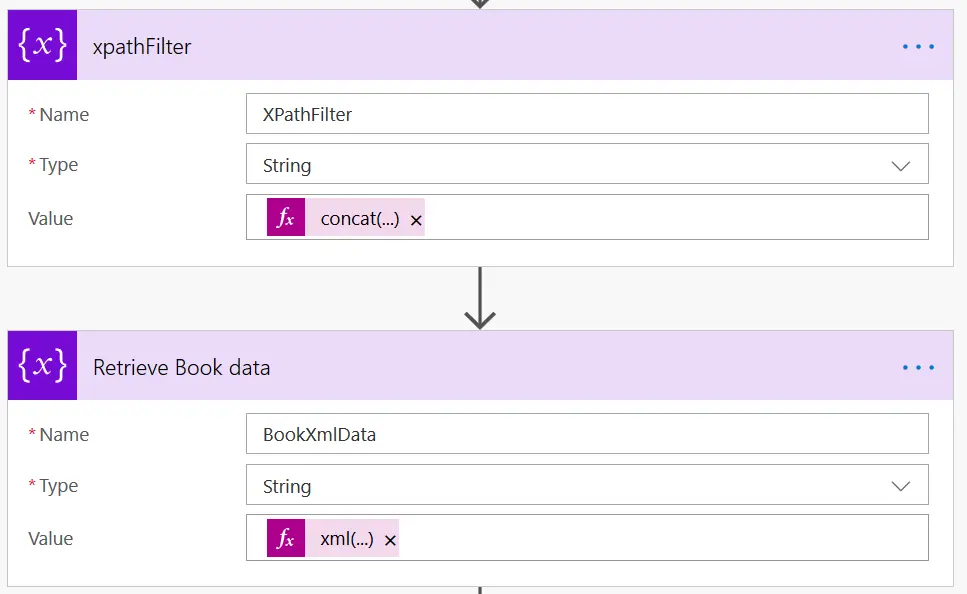
The response of the Retrieve Book data action is a single item element. This element then can be used to execute additional XPath queries against to retrieve properties that are normally not available in your RSS flow. For instance in the Goodreads RSS you can then create a new variable or inject directly into your action the following XPath:
xpath(xml(variables(‘BookXmlData’)), ‘string(/item/user_rating)’)
This will retrieve the user_rating for the book you have just added to your read shelve. You can use the XPath to retrieve any property or element from the <item> element you get returned. You can find more resources on how to use XPath on w3schools.
Using flow for tweets
I use the above flow to auto tweet whenever I finish a book on Goodreads. Before I used a recipe in IFTTT that did pretty much the same but didn’t require any hacking. The downside of IFTT is that you cannot tweak it at all. However the plus side is that you do get some better results in the RSS action than flow provides out the box. However now that I figured out how to retrieve all XML properties using XPath I feel I can use the same approach for some other scenario’s as well. I am a bit sad that the HTTP trigger will move to premium though.